
 HTMLの簡単な解説
HTMLの簡単な解説
HTMLの入門講座です。このステップではHTMLについて簡単に解説します。
更新:
環境:windows10/Microsoft Edge/VS Code

PREPARATION
想定する読者と前提条件
基本的なパソコン操作ができること。HTMLを知らなくてもOKです。ただし、好奇心が必要です。

START
サンプルファイルのダウンロード
この節では、サンプルファイルを使用し作業していきますので、まずは下記サンプルファイルをダウンロードしてください。rakuraダウンロードが完了したら、デスクトップに解凍してください。
STEP1と同様のファイルを使用します。STEP1でダウンロード済みの場合はダウンロード不要です。

hello_htmlのファイル構成
-
images
- bird.jpg
- index.html
HTMLの解説
ここでは、HTML(ハイパーテキスト マークアップ ランゲージ/Hypertext Markup Language)とはそもそも何かについてまずお話いたします。
HTMLってなんですか?
HTMLとは、皆さんが普段使用する容器や小物入れみたいな物と捉えてください。
例えば、お金を入れる貯金箱、コーヒー豆を保存する容器、作り置きした料理を入れるタッパー等、用途に合わせて適切な入れ物に選んで使用していますよね? 聡明な皆さんは、貯金箱に料理は入れないですし、コーヒー豆と一緒にお金を入れることは無いはずです。
つまりHTMLとは、適切な容器に適切な物をしまうための仕組みと言えます。
適切な容器?
HTMLは、文字に目印を付け分かりやすく構造化するための物です。この「文章を構造化するための目印を付ける」仕組みは、文字の中に埋め込むマークアップ(Markup)という目印を通じて行われます。
マークアップは、文章の中の一部分の表現が文書全体の中でどのように関係しているのかを示すことで、文字に意味を持たせることができます。 例えば、近くの本を手に取ってもらえればその本の重要な部分が太い大きな文字で表現されることで見出しであると判断できるはずです。
しかし、コンピューターには、目もなければ耳もありません。与えられた情報の区切りもわからなければ、大きさも太さも判別ができないのです。 そこで、コンピューターに「ここは重要だ」とか、「ここは著者だよ」、「出版日はここ」と教えてあげる為の仕組みがマークアップです。
情報を容器に入れる
HTMLでは情報を要素(element)と言う単位に分割します。
ここで言う要素とは現実世界の入れ物(容器)のことで、情報を詰め込んで、ラベルを付けることによって、コンピューターに優しい意味のある情報にすることができるのです。
もちろん、容器をさらに大きな容器に入れることも可能です。作り置きした料理を入れた容器を冷蔵庫にしまう、そんなイメージを持つと分かりやすいかもしれません。
タグの確認
<h1>初めてのHTML</h1>
<main>
<img src="images/bird.jpg" alt="鳥のイラスト">
<p>これからHTMLの世界に飛び出してみよう!</p>
</main>
先ほどのHTMLの一部をもとに説明していきます。マークアップのシンボルは小なり記号(<)と大なり記号(>)で区切られます。
<h1>や<p>がシンボルの例でタグ(tag)と呼ばれるものです。
例えば、<h1>は要素の始まりを意味し、</h1>は要素の終わりを意味しています。図解すると以下のようになります。

- 境界の決定
- <h1>と</h1>は、h1要素に含まれるテキストやタグの始点と終点を示しています。
- 役割を付与
- h1のhはheading(見出し)の略称であり、この要素に「見出し」という役割(意味)を与えています。
空要素
img要素についてみていきましょう。この要素には、終了タグを意味する</img>がありません。
<img src="images/bird.jpg" alt="鳥のイラスト">
これは、img要素が空要素であるからです。空要素とはデータ(Content)を持たず、その代わりにその場所で利用されるべき情報(この場合では画像)を記述しています。
この場合、src="images/bird.jpg"が画像の指し示す場所になっています。 このsrcを属性の名前、"images/bird.jpg"を値と言います。
この属性は、要素のプロパティを定義するために用いられます。要素毎にいくつか続けて書くことができます。複数の属性を続けて書く場合、間を半角の空白1つ以上で区切る必要があります。
記入方法は、属性名="値"の形になります。属性は、空要素以外にも通常の要素にも使用することができます。

先ほどの例では、img要素の終わりを>で表記していますが、/>と表記しても間違いではありません。 空要素を/>で表記することはXMLの名残であり、どちらで表記しても問題ありませんが、>をここでは推奨しています。
以下は同じ意味。
<img src="images/bird.jpg" alt="鳥のイラスト" />
<img src="images/bird.jpg" alt="鳥のイラスト" >
また、属性値は"(ダブルクォーテーション)で囲んでいますが、'(シングルクォーテーション)でも問題ありません。また、囲まなくても問題ないケースがあります。これについては実際に、使用する際に詳しく解説します。
以下は全て正しい。
<input disabled>
<input value=aaabbb>
<input type='checkbox'>
<input name="kamo san">
タグは、重複することなく、その要素が互いの中に完全に入れ子になる必要があります。
ダメな例:strong要素の終了タグがp要素の外にある。
<p>HTMLの学習を<strong>楽しく行いましょう。</p></strong>
大丈夫な例:
<p>HTMLの学習を<strong>楽しく</strong>行いましょう。</p>
HTMLファイルを見ていこう
では、解凍したHTMLファイルをウェブブラウザで表示してください。index.htmlファイルの中身とウェブブラウザの表示を見比べてみましょう。
まずは、そこからスタートします。下記の図を見てください。1〜4がHTMLのどこに対応しているのかを表しています。 ゆっくりでいいので、良く見比べてください。

<!DOCTYPE html>
DOCTYPEについて、実は皆さんが知るべき内容はほとんどありません。この<!DOCTYPE html>がHTMLファイルの最初の行に存在する必要がある。それだけで十分です。
※大文字小文字の区別をしないため、<!doctype html>も正しい記述となります。
もう少し詳しく知りたい方は読み進めてください。
そもそもDOCTYPEとは、文書型宣言(Document Type declaration)のことを指します。文書型宣言には、文書(この場合HTML)の文法を記述した文書への参照が記述されます。
少しだけ歴史を戻って、HTML5の1つ前のバージョンであるHTML4の時代のDOCTYPEを見てみましょう。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">先ほど記載した「文法を記述した文書」はhttp://www.w3.org/TR/html4/strict.dtdというファイルがそれに該当します。(一度目を通してみることをお勧めします。ざっくりと眺める程度で)
これはDTD(Document Type Difinition)文書型定義と呼ばれるものです。この宣言によりHTMLファイル内に記述できる文法(タグ・属性等)などを指定できます。
もう1つの意味合いとしては、記述したHTMLファイルがDTDで定義した規則に従っているかどうかを解析・チェックするために使用されていました。 これが、HTML5では上記の通り簡素化した表現になります。
引用:DOCTYPEは時代に合わなくなった理由のために必要である。省略した場合、ウェブブラウザは一部の仕様と互換性のない異なるレンダリングモードを使用する傾向がある。文書内でDOCTYPEを含めることは、ウェブブラウザがベストエフォートな試みをすることを保証する。
例えるならば、古いテレビでも放送が見られるようにするための保険的な役割です。これがないと古いテレビでは、放送が正しく視聴できない可能性がある。そんなイメージを持つと良いかもしれません。
<html lang="ja-JP">
html要素は、HTML文書のルートを表す。(ルートという呼び方については、HTML全体がツリー構造になっていることに由来します。)
html要素にlang属性を指定することが推奨されます。langは、languageつまり言語のことであり、このHTML文書がどの国の言葉で書かれているのかを設定します。
みなさんのWebサイトでは日本語を使用するため「ja」または「ja-JP」が適切です。 jaは日本語であり、ja-JPは日本という国の日本語と言う表現になります。日本の場合1国でしか使われていませんが、英語の場合どの国の英語なのかを具体的にするため、en-us(アメリカ英語)、en-gb(イギリス英語)と区別します。
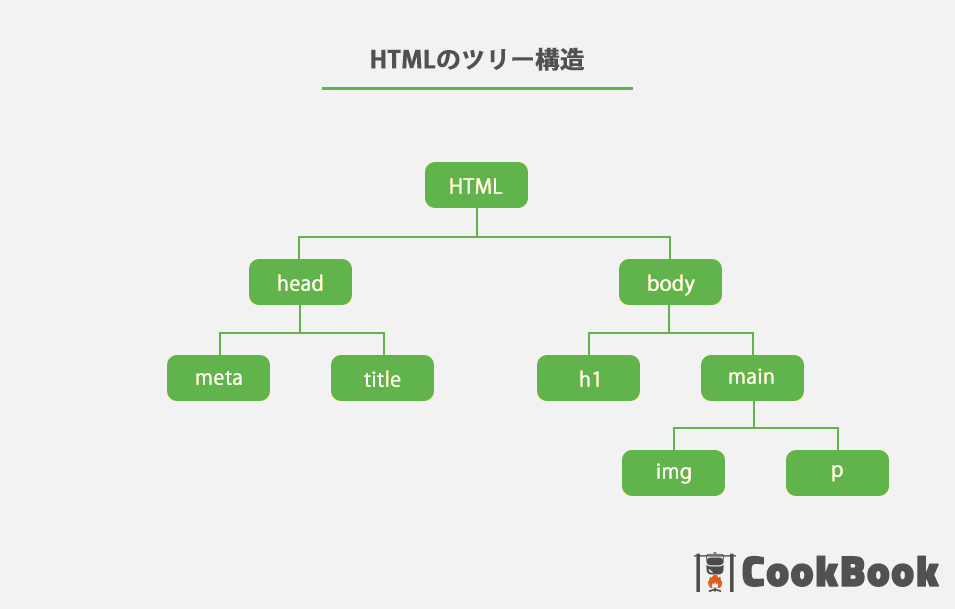
HTMLのツリー構造のイメージ
-
html要素
-
head要素
- meta
- title
-
body要素
- h1
-
main要素
- img要素
- p要素
-
head要素
<head>~</head>
head要素は、HTML文書に関するメタデータの集まりを表します。つまり、表示される部分ではなく、ページに関する情報を含んでいます。
メタデータは、meta要素で表されます。 今知るべき内容はあまり多くはありませんし、退屈な内容なのでこのくらいで。 この内容についてはステップが進むにつれ明らかになるでしょう。
<meta charset="utf-8">
charset属性は、HTML文書で使用される文字コードを指定します。
このHTMLファイルがUTF-8 という文字コードを使用しているということをウェブブラウザ伝えるためのものです。
現段階においては、UTF-8は世界中の大半の文字を表現することができ、HTMLで一般的に使用される文字コードであるという理解で構いません。 ○="△"の記述は,○に△を設定すると読み替えてください。=は数学的等号ではなく、代入と読み替えてください。 この場合、charsetにUTF-8を設定すると言う意味になります。
<title>ハローHTML</title>
title要素は、HTML文書のタイトルまたは名前を表します。ブックマークや検索結果等で使用されています。
<body>〜</body>
body要素は、HTML文書のコンテンツを表します。実際にウェブブラウザに表示される部分です。
<h1>初めてのHTML</h1>
HTML文書コンテンツの見出しを表すh1要素です。
見出しの要素は、h1,h2,h3,h4,h5,h6まであり、要素名の数字で与えられたランクを持ちます。h1要素が最も高いランクであり、h6要素が最も低いランクです。 本の構造をイメージすると分かりやすいかもしれません。
<h1>本のタイトル</h1>
<h2>第1章</h2>
<h3>第1章 - 第1節</h3>
<h4>第1章 - 第1節 - 第1項</h4>
<h4>第1章 - 第1節 - 第2項</h4>
<h3>第1章 - 第2節</h3>
<h4>第1章 - 第2節 - 第1項</h4>
<h4>第1章 - 第2節 - 第2項</h4>
<h2>第2章</h2>
<h3>第2章 - 第1節</h3>
<main>〜<main>
main要素は、HTML文書の主要なコンテンツを表します。HTML文書中1つのみしか使用できません。(ただし例外あり)
<img src="〜" alt="〜" >
ウェブブラウザ上に画像を表示させるために、img要素およびsrc属性を使用します。alt属性は、画像の説明を記載します。
<p>〜</p>
p要素は、段落(paragraph)を表し、一塊の文章を表します。
HTMLファイルを編集してみよう!
VS Codeとウェブブラウザの使い方に慣れるために、HTMLの修正及び表示の更新を行ってみましょう。
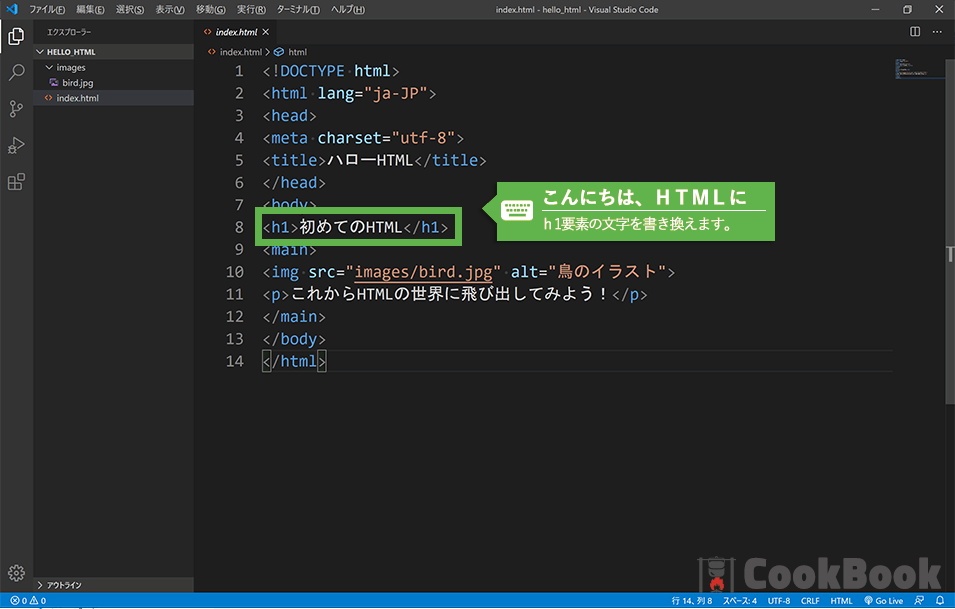
4-1h1要素の編集
h1要素の内容を「初めてのHTML」から「こんにちは、HTML」に変更してみよう。
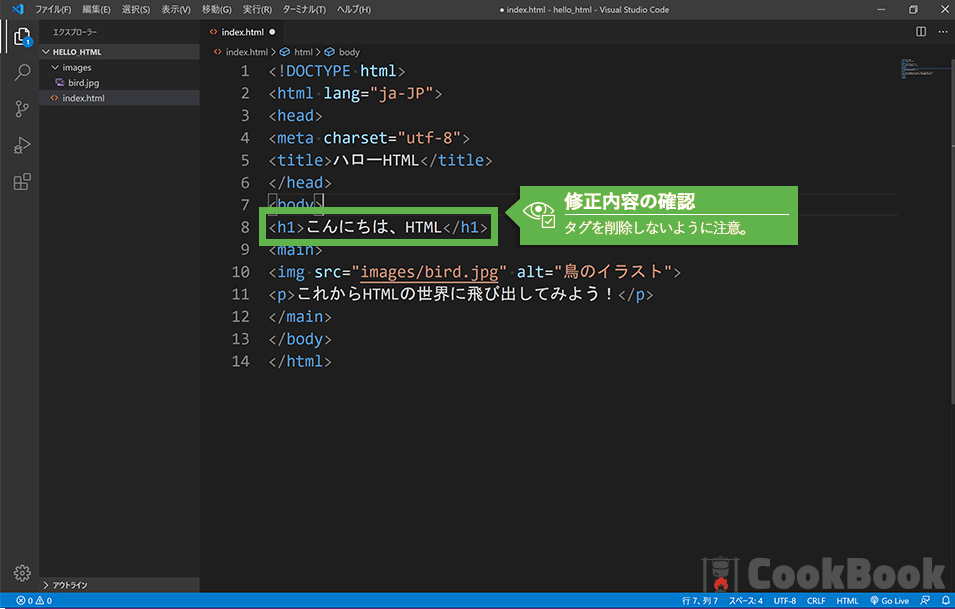
4-2完成版
完成版と見比べてみよう。
上書き保存をするには、CTRL+Sを押して保存してください。
4-3表示の更新
ウェブブラウザの更新ボタンをクリックして、h1の表示内容が変わっていることを確認しよう。

TRY
挑戦してみよう!
- title要素の内容を「おはようHTML」に変更し、表示を確認しよう。
- 文字コードを「utf-8」から「 shift-jis」に変更し、表示を確認しよう。
- 文字コードを「utf-8」に戻し、表示を確認しよう。

PROBLEM

COMPLETE
SKILL
習得スキルボード
- HTMLの基礎知識。
- HTMLファイルの編集及びウェブブラウザでの表示更新方法。